How to Do a Gradient Lip Look
Mastering the Gradient Application
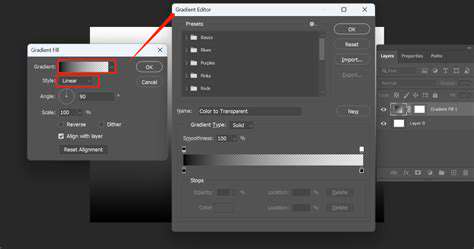
Understanding the Fundamentals of Gradient Descent
Gradient descent is a fundamental optimization algorithm used in machine learning to find the minimum of a function. It works by iteratively moving in the direction of the negative gradient of the function, aiming to reach the lowest point. This iterative process involves calculating the gradient at each step, which represents the direction of the steepest ascent, and then taking a step in the opposite direction to descend. This process continues until a minimum is reached, or a predetermined tolerance is met.
A crucial aspect of understanding gradient descent is appreciating the concept of the gradient itself. The gradient is a vector that points in the direction of the greatest rate of increase of a function. Consequently, moving in the opposite direction of the gradient allows us to descend towards the minimum of the function. This iterative process of calculating and moving against the gradient is the core mechanism behind many machine learning algorithms.
Choosing the Right Learning Rate
The learning rate is a critical hyperparameter in gradient descent that dictates the size of the steps taken towards the minimum. A learning rate that is too small leads to slow convergence, while a learning rate that is too large can cause the algorithm to overshoot the minimum and fail to converge. Finding the optimal learning rate often requires experimentation and tuning, as it can significantly affect the performance of the algorithm.
Dealing with Local Minima
Gradient descent, while powerful, can sometimes get trapped in local minima. A local minimum is a point where the function value is lower than in its immediate surroundings but not the absolute global minimum. Advanced optimization techniques, such as momentum-based methods, can help the algorithm escape these local minima and potentially find the global minimum.
Implementing Gradient Descent in Practice
Implementing gradient descent involves several key steps. First, you need to define the function you want to minimize. Then, you need to calculate the gradient of that function. Next, you need to choose an appropriate learning rate and initialize the parameters. Finally, you need to iteratively update the parameters based on the calculated gradient. Each iteration involves calculating the gradient and then updating the parameters in the opposite direction. This process is repeated until the algorithm converges to a minimum or a predetermined tolerance is met.
Variations of Gradient Descent
Several variations of gradient descent exist, each with its own advantages and disadvantages. Stochastic gradient descent (SGD) updates parameters after each data point, making it faster in some cases but potentially more erratic. Mini-batch gradient descent falls between batch gradient descent and SGD, using smaller batches of data for updates. These variations can significantly impact the efficiency and stability of the optimization process. Understanding the nuances of these methods is crucial for selecting the optimal approach for a given problem.
Advanced Optimization Techniques
Beyond the basic gradient descent algorithm, several advanced techniques enhance optimization. Methods like Adam and RMSprop introduce momentum and adaptive learning rates, accelerating convergence and improving handling of noisy gradients. These techniques often incorporate adaptive learning rates for each parameter, adjusting the step sizes based on the historical gradients. Implementing these more sophisticated methods can lead to a significant improvement in the overall performance of a machine learning model, especially in complex and high-dimensional scenarios. Understanding these nuances is key to effective model training.
Tips for Maintaining Your Gradient Lip Look
Prep is Key
Achieving a flawless gradient lip look starts with proper preparation. Exfoliating your lips gently removes dead skin cells, revealing smoother, more even skin that will allow the color to apply more evenly and prevent the gradient from looking streaky or patchy. Using a lip primer is also beneficial. A lip primer creates a smooth surface for the lipstick or lip gloss to adhere to, preventing feathering and smudging, and keeping the color vibrant throughout the day.
Additionally, consider using a lip liner to define the shape of your lips and create a base for the gradient. A well-defined lip line provides a clean edge for the gradient to build upon, making the color transition smoother and more precise. If you're using a darker shade for the outer lip, using a lip liner in that color can add to the gradient effect and make your lips appear more full.
Mastering the Gradient Technique
The key to a successful gradient lip look lies in the application method. Using a lip brush, or even your fingers, allows for precision and control when applying different shades. Start by applying the lighter shade, focusing on the center of your upper and lower lips. Then, gradually transition to the darker shade, working your way outwards towards the outer edges of your lips. This method will create a natural-looking color gradient.
Experiment with different color combinations for unique looks. A soft pink to coral gradient will create a sweet and approachable look, while a bold red to deep berry gradient can make a striking statement. Don't be afraid to get creative with your choices; the possibilities are endless!
Maintaining Your Gradient All Day
To keep your gradient lip look intact throughout the day, consider using a lip balm or gloss with a slight tint. This will add a touch of hydration and color while maintaining the gradient effect. This will also prevent the color from fading too quickly. Additionally, setting the gradient with a translucent powder or lip setting spray can help to lock in the color and keep it in place for extended wear. This prevents smudging and ensures the gradient stays vivid throughout the day.
Eating and drinking can sometimes disrupt the perfect gradient. To minimize the impact, consider applying a lip balm or gloss as a barrier. This will help to protect the gradient from staining or smudging. Carry a small lip brush or a tissue to touch up any minor smudges or fading throughout the day.
Read more about How to Do a Gradient Lip Look
![Skincare Tips for Winter [Hydration Focus]](/static/images/29/2025-05/HydratingfromWithin3ATheRoleofDietandHydration.jpg)









Hot Recommendations
- Grooming Tips for Your Bag and Wallet
- Best Base Coats for Nail Longevity
- How to Treat Perioral Dermatitis Naturally
- How to Use Hair Rollers for Volume
- How to Do a Graphic Eyeliner Look
- Best DIY Face Masks for Oily Skin
- Guide to Styling 4C Hair
- Guide to Improving Your Active Listening Skills
- How to Fix Cakey Foundation
- Best Eye Creams for Wrinkles